|
Question: I
directed this question to
Matt Cutts,
a software engineer who is the head of Google's Webspam team.
|
I tried to use Google's
text cache to find out when Google was last able to
cache the Web page formerly at http://www.eurunion.org/infores/. I used the
qualifier strip=1 so that the cache wouldn't draw
from the site itself. The URL I entered was:
http://209.85.165.104/search?q=cache:1yM3ON0i3LMJ:www.eurunion.org/infores/+%22accessing+european+union%22+site:http://www.eurunion.org&hl=en&ct=clnk&cd=2&gl=us&lr=lang_en&strip=1
If
you try this, you will see that the cache attempts
to load, but then something (a redirect?) causes it
to display a 404 error. Is my understanding - the
text cache doesn't pull data from the site's servers
- incorrect? Or is something else causing it not to
open? |
Matt Cutts:
Good question. &strip=1 removes the JavaScript/images from a
page, which prevents JavaScript redirects.
It looks like this page has a meta
refresh, which strip=1 doesn't remove. If you install
the "RefreshBlocker"
plugin for Firefox, then you can see the content:
<HTML>
<HEAD>
<META http-equiv="Refresh" content="0;
URL=http://www.eurunion.org/infores/home.htm">
</HEAD>
<BODY>
This page has moved to a <A href="index.htm">new location</A>.
</BODY>
</HTML>
(I removed the spaces.)
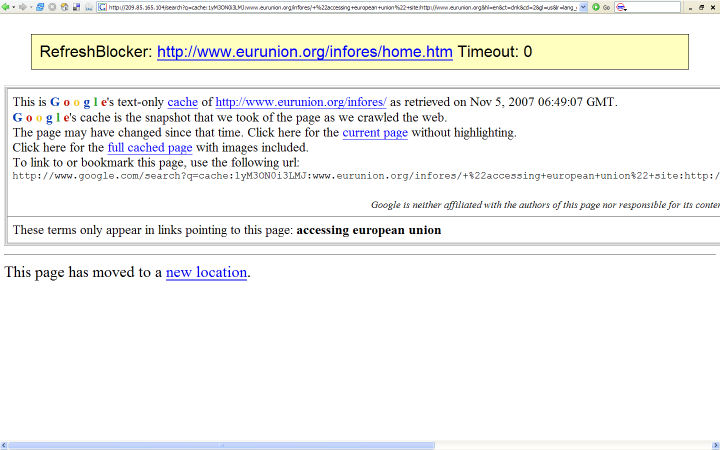
Editor: Below is a
screenshot of what you see with RefreshBlocker. Please note, as Matt
indicates, the plugin works only when a Web page uses the meta tag,
"refresh." It does not work to block Javascript redirects.
 |

